구글 딥마인드, 강화학습 알고리즘 설계 AI 최초 적용
기존 인간 설계 강화학습 모델보다 뛰어난 성능 증명
7일 LG AI연구원 창립행사서 발표

알파고에 이어 알파스타, 알파폴드2까지 선보이며 연일 화제에 오르고 있는 딥마인드의 오준혁 선임연구원이 강화학습에 대한 최신 연구 성과를 공개했다. 강화학습 알고리즘 설계에 인간 대신 AI를 도입해 기존 모델보다 대폭 성능을 개선한 것.
오준혁 딥마인드 선임연구원은 7일 LG AI연구원 출범 행사에서 강화학습에 대한 최근 연구 성과를 발표했다.
연구에서는 AI 기본 원리를 강화학습 알고리즘 개발에 적용, 데이터 기반 AI 학습으로 적합한 알고리즘을 만들어내는 모델을 구축했다. 실험 결과, 기존 인간 제작 알고리즘보다 월등한 성능을 보였다. 단순한 환경에서 만들어진 알고리즘을 경험한 적 없는 복잡한 환경에 적용했을 때도 인간 제작 알고리즘과 비슷한 성과를 거뒀다.
오준혁 딥마인드 선임연구원은 미시건대 박사 시절 딥마인드 인턴쉽을 지내면서 알파고 성과에 감명받아 진로를 결정했다. 2018년 6월 박사학위를 받자마자 영국 런던으로 건너가 딥마인드에 합류해 현재 선임연구원으로 근무 중이다.
서울대 졸업 후 IT업체에서 산업기능요원으로 온라인 게임 개발을 했던 오 박사는 애초 딥러닝에 관심을 가지고 있었다. 미국 미시건 대학 박사과정 입학 후 강화학습 전문가인 이홍락 교수와 사틴더 교수의 지도를 받으며 이 분야에 뛰어들었다.
딥마인드 연구팀은 강화학습 알고리즘 제작 AI 모델에게 기본적인 강화학습 개념과 관련된 모든 룰을 학습시켰다. 특히 업데이트룰(LPG)이라는 방법을 도입한 것이 새로운 점이다. 오준혁 연구원은 “룰에도 뉴럴네트워크를 적용해 점차 개선되도록 만들었다. 에어전트 학습 과정은 모두 미분이 가능하다는 것에서 착안했다”고 설명했다.
모델 훈련은 3개 종류 도메인(Tabular grid worlds, Rando, grid worlds, Delayed chain MDP)과 각 도메인 당 5개 변수를 가진 15가지 환경에서 이뤄졌다.
훈련 후에는 기존 인간 설계 알고리즘 A2C와 연구팀이 이번 실험을 위해 개발한 인간과 AI 합동 설계 알고리즘 LPG-V와 성능을 비교했다. 테스트 결과, 인간 설계 A2C와 LPG-V보다 훨씬 성능이 뛰어난 것으로 나타났다.
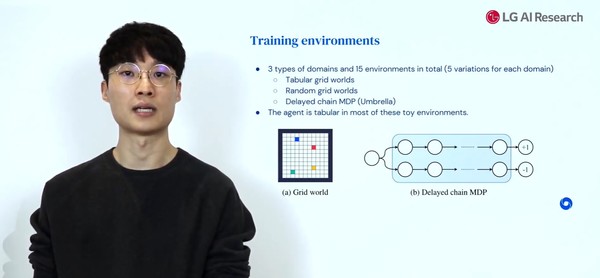
오준혁 박사가 설명한 AI 설계 강화학습 훈련 환경
학습해본 적 없는 새로운 요소가 많으면서 극도로 복잡한 아타리(Atari) 환경에도 적용해 기존 모델과 성능을 비교했다. 결과적으로 2015년 딥마인드 모델 성과와 거의 동일한 성과를 보였다. 오준혁 연구원은 “이전에 본 적 없는 복잡한 아타리 게임에서 전문가가 손수 디자인한 알고리즘과 유사한 퍼포먼스를 보인 것은 연구진 입장에서도 놀라웠다”고 강조했다.

인간 설계 알고리즘 활용 강화학습 모델보다 월등한 성과를 보였다
딥마인드 연구팀은 향후 알고리즘 성능 개선을 위해 학습 환경, 데이터 가지 수를 늘릴 계획이다. 오준혁 연구원은 “데이터와 환경이 방대하고 다양해지면 기존 강화학습 알고리즘보다 훨씬 성능이 좋아질 것”이라고 말했다.
이번 성과 의미에 대해 그는 “강화학습이 게임과 같은 주어진 문제를 푸는 데서 나아가 알고리즘 자체를 구축하는 것도 가능해진 것이다. 미래에는 AI가 알고리즘도 스스로 디자인할 수 있을 것”이라고 전했다.
해당 연구는 6일부터 진행 중인 글로벌 AI 컨퍼런스 NeurIPS에서도 공개할 예정이다.
- [2020/12/28] 딥마인드의 새로운 AI알고리즘 '뮤제로', "알파고보다 더 센놈이 나타났다" (1)
- [2020/12/02] 구글 딥마인드, 또 혁명적 성과…생로병사의 비밀 푸나 (1)